Datatyper | |
| forrige | Arbejd med data | næste |
Der er ni hovedtyper af dataobjekter i Kst. Dataobjekter kan indeholde visse andre dataobjekter, som repræsenteres af træstrukturen som vises i datahåndteringsvinduet. Følgende plot anskueliggør forholdet mellem de forskellige datatyper.
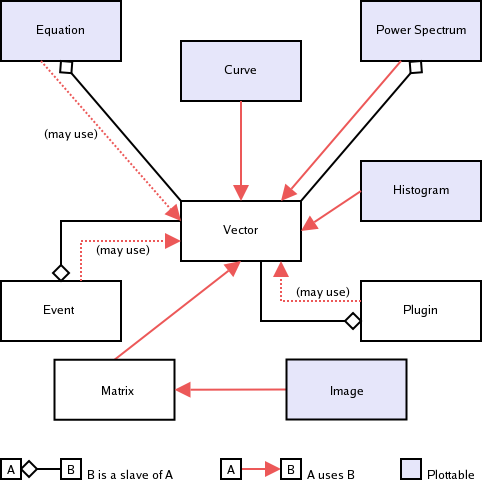
Som det ses i diagrammet ovenfor, er dataobjekterne kurve, ligning, histogram, effektspektrum og billeddataobjekter de eneste dataobjekter som kan plottes. Alle dataobjekter (andet end vektorer) har mulighed for at bruge vektorer, mens ligninger, effektspektre, begivenheder og plugin alle indeholder slavevektorer.
Beskrivelser af hver datatype varetages nedenfor, sammen med oversigter over de indstillinger og valgmuligheder der er tilgængelige når hver type dataobjekt laves eller redigeres. Indstillinger som er fælles for næsten alle datatyper er udeladt: Se Opret nye dataobjekter for mere information.
Vektorer er et af de oftest bruge dataobjekter i Kst. Som navnet angiver, er vektorer helt enkelt ordnede lister med tal. Oftest indeholder de X- eller Y-koordinaterne for et sæt datapunkter.
Eftersom vektorer potentielt kan være rigtigt store, er det en god idé at være klar over hvor meget hukommelse som Kst har tilgængelig til brug. Aktuelt tilgængeligt hukommelse vises i statuslinjens nedre højre hjørne i Kst's hovedvindue.
Hvis statuslinjen ikke er tilgængelig, så sørg for at er markeret i menuen .
Det følgende er et skærmaftryk af vinduet som vises når vektorer laves eller redigeres. Forklaringer af indstillingerne er på listen nedenfor.
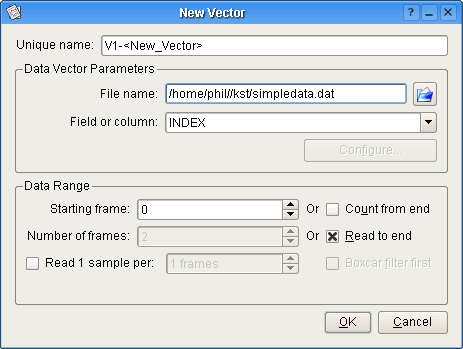
Kildefilen og felter der skal læses kan sættes med følgende valgmuligheder.
Søgestien til den ønskede datafil. Ved at klikke på knappen til højre vises et filsøgervindue, som kan bruges for at søge hen til filen på en grafisk måde.
Feltet eller søjlen som en vektor skal laves ud fra.
Dette afsnit angiver dataintervallet som skal bruges i datavektoren for det valgte felt.
Ved at bruge disse fire indstillinger, kan nederste og øverste grænse for dataintervallet angives. For eksempel for at læse fra ramme 10 til 900, skrives 10 for Startramme og 890 for Antal rammer. For at læse fra ramme 500 til filens slutning, skrives 500 for Startramme og punktet Læs til slutningen markeres. For kun at læse de 450 sidste rammer fra filen, markeres punktet Tæl fra slutningen og der skrives 450 for Antal rammer. Kombinationerne som bruges i de to foregående eksempler er ofte nyttige for at læse data fra en fil som opdateres i realtid. Efterfølgende tilføjelser til filen læses, hvilket gør at de tilhørende vektorer også opdateres.
Foruden nedre og øvre grænse for dataområdet, kan samplingerne som skal læses fra det valgte intervallet angives. Hvis Læs en sampling pr ikke er markeret, læses alle samplinger i det valgte intervallet. Hvis Læs en sampling pr er markeret, læses kun en sampling pr N rammer, hvor N er antallet som skrives ind i feltet til højre. Værdien af den sampling som bruges til at repræsentere en ramme afhænger af om Lavpasfilter først markeres. Hvis Lavpasfilter først ikke er markeret, er værdien den samme som første sampling i rammen. Hvis Lavpasfilter først er markeret, er værdien middelværdien af alle samplinger i den specielle ramme.
Kurver bruges i hovedsagen til at oprette objekter der kan plottes ud fra vektorer. Kurver laves af to vektorer, en “X-aksevektor” og en “Y-aksevektor”, som antages at sørge for et sæt datapunkter. Altså kan en kurve ses som et sæt datapunkter og linjerne som forbinder dem (selv om punkterne eller linjerne måske ikke er synlige i plottet).
Det følgende er et skærmaftryk af vinduet som vises når kurver laves eller redigeres. Forklaringer af indstillingerne er på listen nedenfor.
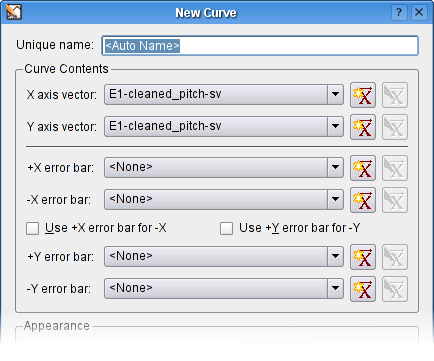
Indholdet i kurven kan indstilles i dette afsnit.
Vektoren der skal bruges for den uafhængige (vandrette) akse.
Vektoren der skal bruges for den afhængige (lodrette) akse.
Vektorerne som indeholder fejlværdier som svarer til de respektive X-aksevektor og Y-aksevektor. Vektorerne skal indeholde fejlbjælkernes størrelse i samme rækkefølge som datapunkterne.
X/Y-fejlbjælke for -X/YHvis dette er markeret, tegnes fejlbæjlkerne symmetrisk omkring datapunkten. For at tegne asymmetriske fejlbjælker i X- eller Y-retningen, afmarkeres feltet og en vektor for fejlbjælkernas længde vælges under datapunktet i dropned-feltet -X/Y fejlbjælke.
X/Y-fejlbjælkeVektoren som skal bruges til fejlbjælken under datapunktet. Se foregående paragraf for mere information om at bruge asymmetriske fejlbjælker.
Et ligningsdataobjekt består af et matematisk udtryk og en uafhængig variabel. Udtrykket bygges op ved at bruge en kombination af skalarer, vektorer og operatorer, og repræsenterer oftest den afhængige variabels værdier. Den uafhængige variabel kan være en eksisterende vektor eller kan laves når ligningsobjektet oprettes eller redigeres. Eftersom en ligning i sluttilstanden består af et sæt datapunkter, er et ligningsobjekt der kan plottes.
Det følgende er et skærmaftryk af vinduet som vises når ligninger laves eller redigeres. Forklaringer af indstillingerne er på listen nedenfor.
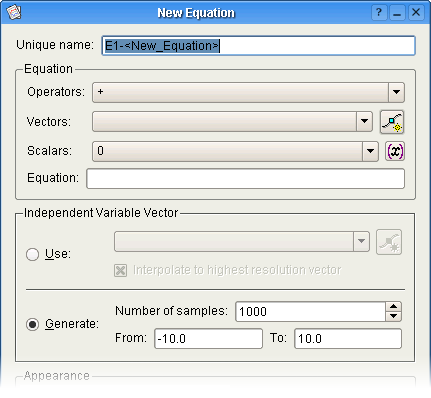
Det matematiske udtryk som repræsenterer den afhængige variabel kan ændres i dette afsnit.
En liste med tilgængelige operatorer. Ved at vælge en operator i listen indsættes den ved den nuværende markørpositionen i tekstfeltet Ligning.
En liste med nuværende vektorobjekter i Kst. Ved at vælge en vektor i listen indsættes den på den nuværende markørpositionen i tekstfeltet Ligning.
En liste med tilgængelige skalarværdier. Listen består både af skalarværdier i nuværende session i Kst, samt nogle indbyggede konstanter. Ved at vælge en skalar i listen indsættes den på den nuværende markørposition i tekstfeltet Ligning.
Det matematiske udtryk som repræsenterer den uafhængige variabel. Du kan indtaste det manuelt in tekstfeltet, eller du kan vælge punkter der skal indsættes med dropned-feltet ovenfor.
Dette afsnit bruges til at angive kilden til værdierne for den uafhængige variabel.
Vælg dette for at bruge en eksisterende vektor som uafhængig variabel. Vælg en vektor i dropned-feltet, eller lav hurtigt en ny ved at klikke på knappen til højre.
Ved at vælge dette interpoleres den valgte vektor til det højest mulige antal samplinger.
Vælg dette for at oprette et sæt værdier til at bruge som uafhængig variabel. Angiv den laveste værdi som skal genereres i feltet Fra og den højeste værdi som skal laves i feltet Til. Indstil værdien Antal samplinger til antal ligefordelte værdier der skal laves mellem den laveste værdi og den højeste (inklusive).
Et histogramdataobjekt repræsenterer helt enkelt et histogram for en vis vektor. Histogramobjekter kan plottes.
Det følgende er et skærmaftryk af vinduet som vises når histogrammer laves eller redigeres. Forklaringer af indstillingerne er på listen nedenfor.
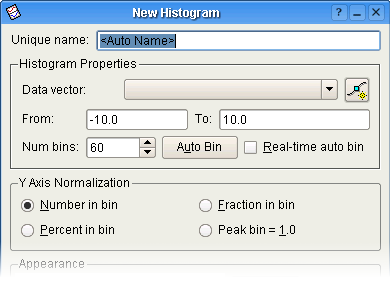
Kildevektoren, samt grundlæggende histogramegenskaber kan ændres fra dette afsnit. Du kan enten angive indstillingerne manuelt eller bruge knappen .
Datavektoren som histogrammet skal laves ud fra. Selvom en vektor kræves for at oprette et histogram, behandles vektoren som en uordnet mængde for det formål at oprette et histogram.
Feltet Fra indeholder venstre grænse for området længst til venstre i histogrammet. Feltet Til indeholder højre grænse for området længst til højre i histogrammet.
Indtast totalt antal områder som skal bruges i feltet Antal områder.
I stedet for at angive værdier for Fra, Til og Antal områder, kan du klikke på for automatisk at oprette værdier for alle tre felter, baseret på de laveste og højeste værdier, samt antal elementer som findes i kildevektoren.
Dette afsnit bruges til at angive typen af normalisering som bruges til histogrammets Y-akse.
Ved at vælge dette kommer Y-aksen til at repræsentere antal elementer i hvert område.
Ved at vælge dette kommer Y-aksen til at repræsentere brøkdelen af antal elementer i hvert område af totalt antal element.
Ved at vælge dette kommer Y-aksen til at repræsente procent af elementer (ud af det totale antal elementer) i hvert område.
At vælge dette får Y-aksen til at repræsentere antal elementer i hvert område divideret med antal elementer i det største område (området med størst antal elementer). Med andre ord normaliseres Y-aksen til 1,0.
Et dataobjekt med et effektspektrum repræsenterer effektspektret for en vektor, defineret som “kvadratroden af absolutværdien af de indflettede Fouriertransformer med længde 2^xaf vektoren”, hvor x er værdien som skrives ind i feltet FFT-længde. Definitionerne nedenfor forudsætter grundkunskab om effektspektre. For yderligere information, se Numerical Recipes in C: The Art of Scientific Computing, publicerad af Cambridge University Press.
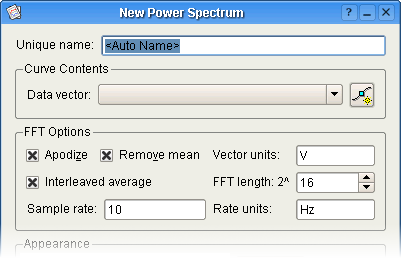
Datavektoren, samt grundlæggende egenskaber for effektspektre kan ændres i dette afsnit.
Datavektoren der skal oprettes effektspektrum ud fra.
Ved at markere Indflettet middelværdi bliver det muligt at angive længden for den indflettede Fouriertransform. Længden angives som en to-potens. Hvis Indflettet middelværdi ikke markeres, afgør Kst længden baseret på vektorens længde.
Enhederne som angives i tekstfelterne bruges til det formål automatisk at generere aksetekster for plottene.
Samplingsfrekvensen bruges til at generere X-aksen i plot med effektspektre.
Hvis dette markeres, apodiseres data med et Hanning-vindue, for at reducere læk fra område til område.
Vælg dette for at fjerne middelværdien fra markeret data (dvs. flytte data så middelværdien er nul).
Et dataobjekt for plugin repræsenterer et plugin i Kst. Alle plugin har et fælles format og vises som typen “Plugin” i datahåndteringen. For mere information om plugin, se Plugin og filtre.
Et dataobjekt for begivenhedsovervågning repræsenterar en udgave af en begivenhedsovervågning. For mere information om at overvåge begivenheder, se Begivenhedsovervågning.
En matrix repræsenterer et sæt tredimensionelle datapunkter (X, Y, Z) arrangerede i et todimensionalt gitter. Z-værdier i matricen hentes fra en vektor, og gitterstrukturen angives manuelt med dialogerne Redigér eller Ny matrix. Beskrivelsen nedenfor refererer til følgende diagram som afbilder Kst's matrixstruktur.

Et skærmaftryk og forklaring af matrix-dialogen følger.
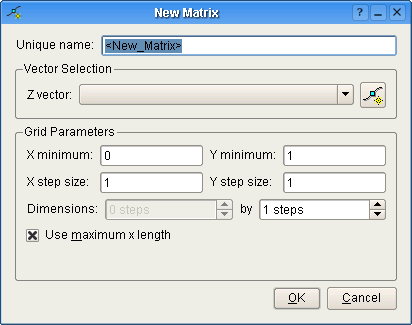
Nulpunktet for matricen angives af koordinaterne (X-minimum, Y-minimum). Stedet for nulpunktet repræsenteres af en rød cirkel i ovenstående diagram.
Disse to værdier angiver dimensionerne for hver rektangulær celle i matrixgitteret. Alle celler i matricen har identiske dimensioner.
Indtast antal trin for matricens X-dimension, efterfulgt af antal trin for matricens Y-dimension. Hvis Brug maksimal x-længde er markeret, afgøres matricens X-dimension baseret på vektorens længde og indtastet Y-dimension. Hvis tilvalget er markeret og vektorens længde derefter ændres, opdateres matricens X-dimension i overensstemmelse med dette.
Bemærk at minimal tilladt Y-dimension er 1, mens minimal tilladt X-dimension er 0.
Billeder er grafiske repræsentationer af matricer. Billeder kan plottes som farvekort, konturkort eller begge.
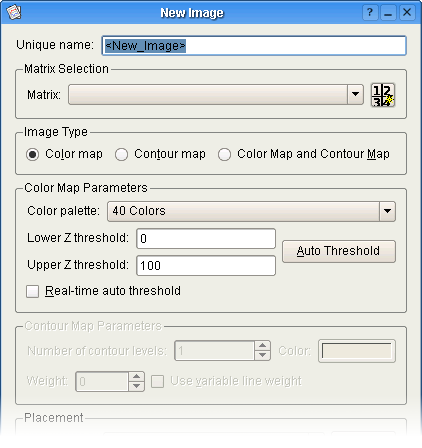
Vælg matricen som bruges til dette billede. Nye matricer kan laves ved at klikke på knappen til højre.
Vælg typen af billede der skal plottes. Ved at ændre dette valg aktiveres eller deaktiveres afsnit af billeddialogen på passende måde.
Et farvekort repræsenterer Z-værdien for hver celle i matricen med en farve. Dette afsnit er kun tilgængeligt hvis Farvekort eller Farvekort og konturkort er markerede under Billedtype.
Vælg den farvepalet som skal bruges til farvekoretn. Normalt er to paletter passende for farvekort installerede af Kst: Kst Grayscale 256 (en gråskalapalet med 256 farver) og Kst Spectrum 1021 (et regnbuespektrum med 1021 farver som går fra blåt til rødt). Yderligere paletter kan installeres ved blot at kopiere paletfiler som virker med GIMP til undermappen colors i brugerens indstillingsmappe (for eksempel /usr/share/config/colors/). Bemærk at billeder som blev gemt med andet end standardpaletten måske ikke kan vises af andre Kst-brugere hvis de ikke har paletten som kræves. I sådanne tilfælde bruges en standard-gråskalapalet i stedet.
Indtast nederste og øverste tærskel der skal bruges til afbildning af farver. Paletfarver fordelas jævnt mellem Nederste Z-tærskel og Øverste Z-tærskel. Alle celler i den valgte matrix med Z-værdier mindre end Nederste Z-tærskel afbildes på den første farve i paletten. Alle celler i den valgte matrix med Z-værdier større end Øverste Z-tærskel afbildes på den sidste farve i paletten. Ved at klikke på fyldes nederste og øverste tarskelværdier ind med den mindste og største Z-værdi som findes i den valgte matrix.
Et konturkort plotter et sæt linjer, hvor hver repræsenterer en vis Z-værdi. Dette afsnit er kun tilgængelig hvis Konturkort eller Farvekort og konturkort er markerede under Billedtype.
Vælg antallet af konturniveauer der skal bruges. Konturniveauerne fordeles jævnt mellem mindste og største Z-værdi som findes i matricen.
Vælg den farve der skal bruges til konturlinjerne. Ved at klikke på knappen vises en almindelig farvevalgsdialog i KDE.
Vælg vægten, eller “tykheden” af konturlinjerne. Hvis Brug variabel linjevægt er markeret, plottes konturlinjer som repræsenterar højere højder tykkere end dem som repræsenterer lavere højder. Brug dette tilvalg med forsigtighed, eftersom billeder med høj konturlinjetæthed kan blive ulæselige.
| forrige | hjem | næste |
| Datahåndteringen | op | Menuen Data |